
Create your own locally hosted family AI assistant
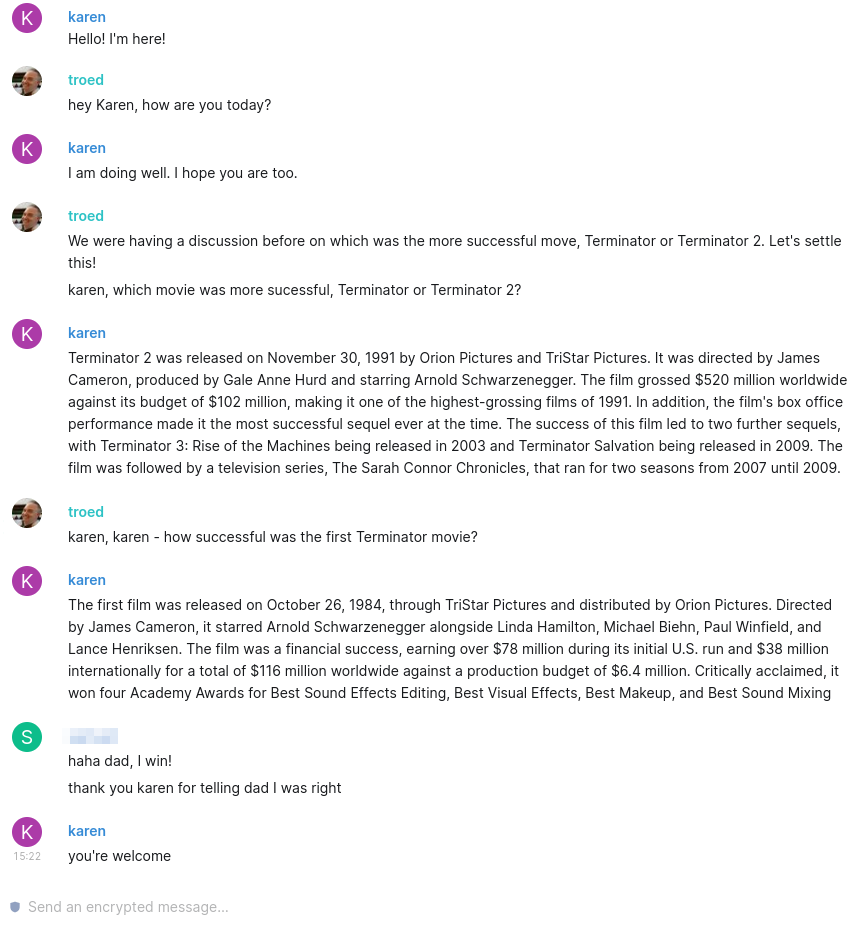
What you’re seeing in this picture is a screenshot from our “family chat”. It’s a locally hosted Matrix server, with Element clients on all the computers, phones and tablets in the family. Fully End2End encrypted of course - why should our family discussions end up with some external party?
You’re also seeing “Karen”, our family AI, taking part in the discussions with some helpful input when so prompted.
Karen is based on the LLaMa 13b 4-bit GPTQ locally hosted LLM (Large Language Model) I mentioned in a previous post. Thanks to Facebook/Meta releasing this model there’s a very active development community working on it at the moment, and I’m making use of a few of those projects to be able to make this happen.
- GPTQ-for-LLaMa - quantizes the original weights of the 13b model down to something that fits a 12GB VRAM GPU
- text-generation-webui - implements a Gradio based Web/API interface to LLaMa et. al.
While I’ve written the glue between our Matrix chat and the text-generation-webui API myself I make use of a very nifty little utility:
- mnotify - allows regular unix cli interfacing to Matrix channels
… and so my code is simply a bunch of Bash shellscripting and a cut down version of the websocket chat example Python code from text-generation-webui. The way I’ve written it I can change context (see below) dynamically during the conversation, for example depending on who is prompting the bot.
Context? Well, yes. This is something not well explained when people just use LLMs like GPT. The model itself contains “knowledge”, but a lot of what creates the experience possible is due to what context is supplied - text included with every interaction influencing the inference and massively changing the tone and content of the responses. This is for example the context I currently use with Karen:
“You are a question answering bot named Karen that is able to answer questions about the world. You are extremely smart, knowledgeable, capable, and helpful. You always give complete, accurate, and very detailed responses to questions, and never stop a response in mid-sentence or mid-thought.”
You might also be able to guess at a few other contexts that might come into action, explaining why the bot is named as it is.
So what’s on the horizon for this technology at the moment?
Well, there are implementations of both Whisper (voice-to-text) and Tortoise-TTS (text-to-speech) in the works so next up I guess I need to make this into a locally hosted “Siri / Alexa”. Just to be clear, if I do, it _will_ be activated with -“Computer.” .